
{kind=link}

Dans notre société moderne, des milliards d’appareils électroniques sont utilisés chaque jour. Une tendance accentuée par la démultiplication de l’Internet des objets (IoT).
Technologie de mesure de pointe et algorithme de regroupement extrêmement rapide, tribune par Kiyoshi Chikamatsu, R&D project manager de Keysight Technologies – Cette croissance s’accompagne d’une menace toujours plus importante en matière de cybersécurité : les chevaux de Troie intégrés dans les puces à semi-conducteurs à des fins malveillantes. Avec l’augmentation de l’externalisation de la conception des circuits, de la fabrication et de l’utilisation de la propriété intellectuelle de fournisseurs extérieurs, les risques liés aux chevaux de Troie sont en hausse. Le déploiement de dispositifs vulnérables pourrait faire courir un risque énorme à notre société, en particulier s’ils ont un impact sur des systèmes critiques comme le chiffrement du commerce électronique, les véhicules à conduite autonome ou les contrôleurs d’aviation. Comme il est essentiel que ces systèmes soient exempts de tout circuit malveillant, la capacité à détecter les chevaux de Troie dans les systèmes électroniques est extrêmement importante.
Récemment, une équipe de recherche dirigée par Nozomi Togawa, professeur à la faculté des sciences et de l’ingénierie de l’université Waseda (Japon), qui a mené des recherches sur la détection des chevaux de Troie, a utilisé un analyseur d’ondes capable d’identifier de petites anomalies dans de très grandes bases de données (>1 téraoctet) grâce à un algorithme avancé grâce au machine-learning. pour améliorer considérablement ses capacités de détection. Dans cet article, nous allons décrire comment ces technologies ont amélioré la détection des chevaux de Troie.
Les défis de la détection des chevaux de Troie
Les chevaux de Troie peuvent causer de graves dommages s’ils permettent l’arrêt du signal et la destruction. Ces opérations peuvent être réalisées en insérant seulement une douzaine de portes dans le circuit lors de la phase de conception (ce qui les rend difficiles à découvrir). La meilleure façon de détecter les chevaux de Troie est de consulter les schémas de circuits ou les signaux de communication du canal principal. Malheureusement, l’externalisation croissante de la conception et de la fabrication des circuits, ainsi que l’utilisation de la propriété intellectuelle d’autres entreprises, font qu’il est difficile de comprendre et de vérifier tous les détails de la conception des puces et des schémas d’entrée/sortie. Il est donc difficile et peu fiable de détecter les chevaux de Troie après la fabrication en examinant le signal du canal principal. D’autre part, le signal du canal latéral du courant d’alimentation contient des informations sur les opérations internes de la puce à semi-conducteurs. Si des activités malveillantes sont présentes, elles apparaîtront sous forme de déviations du courant d’alimentation. Cependant, la détection des chevaux de Troie par la surveillance du courant d’alimentation présente plusieurs défis :
- Mesure de courant à large bande passante et à haute résolution – Les puces à semi-conducteurs fonctionnent à haute fréquence avec de multiples activités simultanées, de sorte que leurs écarts de courant d’alimentation sont fugaces et très faibles : une technologie de mesure du courant à large bande passante et à haute résolution est nécessaire pour identifier l’activité des chevaux de Troie.
- Le machine learning pour l’analyse des données sous forme d’onde – Étant donné que les chevaux de Troie sont des phénomènes heureusement rares, la capacité de mesurer en continu à grande vitesse et avec une haute résolution sans interruption pendant de longues périodes est nécessaire. Cependant, cette collecte de données peut créer des bases de données extrêmement volumineuses. Par exemple, l’enregistrement d’un flux de données de 10MSa/s pendant 24 heures crée une base de données d’une taille supérieure à 1 téraoctet. Il est donc nécessaire d’utiliser une sorte d’algorithme d’apprentissage automatique capable de trier rapidement les énormes bases de données.
Jusqu’à récemment, les technologies existantes ne répondaient pas à ces exigences. Cependant, voici comment il est possible de relever ces défis.
Détection de courant à large bande passante et haute résolution
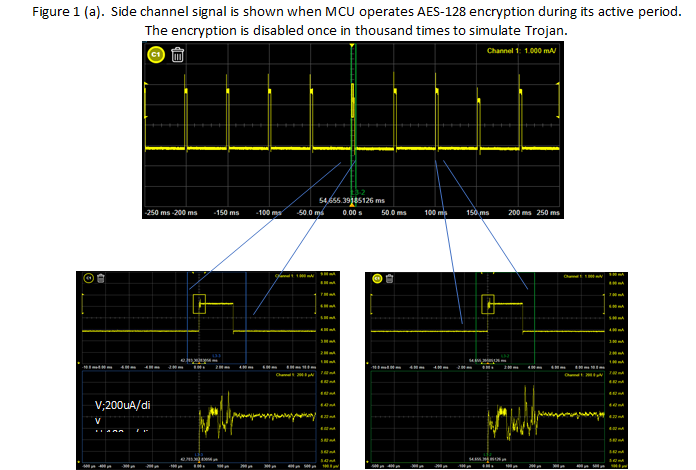
Les figures suivantes montrent un exemple de détection de l’activité d’un cheval de Troie par l’analyse du signal de courant d’alimentation de canal latéral. Dans cet exemple, un MCU basse consommation a été programmé pour chiffrer les données utiles à l’aide d’AES-128 pendant sa période active, aucune activité ne se produisant pendant le mode veille. Dans ce cas, un cheval de Troie désactive occasionnellement le cryptage. Un train d’impulsions de courant d’alimentation infecté par le cheval de Troie est illustré à la figure 1 (a). Il est difficile de distinguer visuellement les impulsions normales et infectées. Les vues agrandies montrent les différences de signal lorsque le cheval de Troie est actif (b) et inactif (c). Il est encore difficile de distinguer les deux signaux. Si la partie initiale des impulsions est agrandie, des différences sont visibles au niveau des micro-ampères avec des composantes de fréquence de plusieurs MHz.
La détection n’est possible qu’en utilisant une technologie de détection de courant à haute résolution et à large bande passante (au-delà des capacités de performance des sondes de courant conventionnelles). Il existe de nombreuses technologies de détection du courant. Par exemple, les sondes de courant à pince les plus courantes ont un courant minimum mesurable d’environ 1-3mA [2]. C’est insuffisant pour la détection des chevaux de Troie. En revanche, certains capteurs de courant t peuvent mesurer des courants aussi faibles que 3μA avec une bande passante allant jusqu’à 100 MHz en utilisant une résistance de shunt interne de 0,41 ohm [3]. Cette capacité de mesure à bas niveau et à large bande passante est rendue possible par un schéma de détection de courant innovant qui combine une détection de courant résistive en courant continu et à basse fréquence avec une détection de courant magnétique à des fréquences plus élevées. En raison de sa faible résistance d’insertion, les pics de courant importants ne peuvent pas provoquer une chute de tension importante du rail d’alimentation suffisante pour déclencher un brown-out du dispositif MCU.
 Le machine learning pour l’analyse des données de mesure volumineuses
Le machine learning pour l’analyse des données de mesure volumineuses
Les algorithmes de machine learning sont classés en deux catégories : supervisé et non supervisé. Le mode supervisé est utilisé pour détecter des modèles connus, tandis que le mode non supervisé est préférable lorsque l’objectif est de détecter des anomalies inconnues, comme la signature créée par les chevaux de Troie. Parmi ces derniers algorithmes, le regroupement est devenu un outil essentiel pour l’analyse des données volumineuses dans de nombreuses applications. Bien que l’implémentation d’algorithmes de machine learning non supervisés utilisant le clustering ait été développée, la plupart n’est pas encore capable de traiter de grandes quantités de données sous formes d’onde. Une base de données de formes d’onde contenant des millions de segments sous forme d’onde, chacun composé de milliers de points de données, représente un défi en termes d’analyse des données. Le tri et la classification d’une base de données aussi massive à l’aide d’algorithmes classiques nécessitent des ressources informatiques importantes et des temps de traitement longs. Cependant, de nouveaux algorithmes traitent d’énormes quantités de données de forme d’onde à l’aide d’une plate-forme PC à faible coût et à une vitesse semblable à celle des grandes solutions de serveur informatique. Le temps de calcul de l’algorithme est linéaire par rapport au volume et à la dimension des données, même si la taille de la base de données de mesure dépasse largement la mémoire principale du CPU (figure 2 (a)). Grâce à de nombreuses innovations, les performances de ces algorithmes exécutés sur un PC standard sont équivalentes à celles d’algorithmes comparables exécutés sur de grands serveurs informatiques contenant 300 à 400 cœurs de processeur. Cela représente une amélioration de la vitesse de x100 à x1000 par rapport aux algorithmes conventionnels.
Pendant l’acquisition des données, le logiciel utilise la fonction de déclenchement de l’oscilloscope pour définir les formes d’onde, qui sont simultanément pré-triées en groupes approximatifs (ou étiquettes) par un processus de marquage en temps réel (figure 2 (b)). Les résultats pré triés sont stockés dans la base de données des étiquettes, qui est un résumé concis de toutes les formes d’onde. La taille de la base de données des étiquettes est d’environ 1/100 à 1/500 de la base de données sans perte, qui contient une archive complète de toutes les formes d’onde. Ces capacités permettent à l’utilisateur de commencer l’analyse immédiatement après la fin de l’acquisition des données. Comme la base de données des étiquettes utilise les méta-données sous formes d’onde, les principales opérations d’analyse des données peuvent être effectuées en 10 secondes ou moins. Les modifications du nombre de clusters et de sous-clustering (décomposition d’un cluster sélectionné en d’autres clusters) sont également très rapides. Si la base de données des étiquettes n’a pas une résolution suffisante pour permettre le sous-clustering, il est possible d’effectuer un clustering détaillé en utilisant la base de données sans perte. En plus de ces fonctions, une capacité de lecture centrée sur les clusters permet de visualiser en temps quasi réel les formes d’onde capturées, ainsi que de localiser rapidement des formes d’onde spécifiques. Cette technologie permet d’identifier rapidement et facilement les formes d’onde, même celles qui ne comptent que pour un million.
 Détection réussie d’un cheval de Troie
Détection réussie d’un cheval de Troie
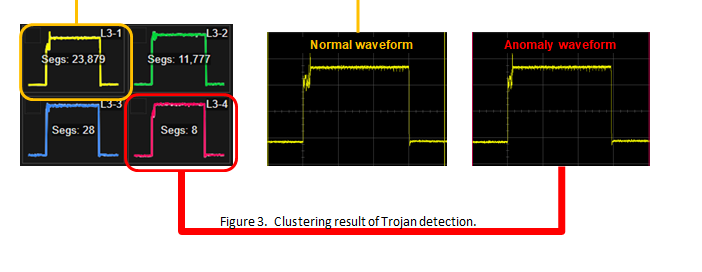
La figure 3 montre un exemple de détection de chevaux de Troie par l’analyse des formes d’onde du courant d’alimentation du canal latéral. Immédiatement après l’acquisition des données, le logiciel a divisé les formes d’onde capturées en quatre groupes. Les deux groupes principaux (codés en jaune et vert) comprennent la majorité des formes d’onde, mais le logiciel peut différencier les formes d’onde infectées (codées en rouge) même si elles ne diffèrent que légèrement des groupes principaux. Ce type d’analyse n’est pas possible avec un oscilloscope et une sonde de courant, car ils ne disposent pas de la résolution et de la bande passante nécessaires. En outre, les algorithmes de machine learning classiques ne peuvent pas traiter des formes d’onde de cette complexité. Seule la combinaison des capacités de mesure de courant dynamique haute résolution à large bande passante et d’un algorithme de clustering ultra-rapide peut fournir un moyen aussi efficace d’identifier les chevaux de Troie.
 Cette technologie a de nombreuses utilisations au-delà de la simple détection de chevaux de Troie matériels, car il s’agit d’un outil très polyvalent permettant de détecter des anomalies dans tout environnement de données de mesure volumineuses.
Cette technologie a de nombreuses utilisations au-delà de la simple détection de chevaux de Troie matériels, car il s’agit d’un outil très polyvalent permettant de détecter des anomalies dans tout environnement de données de mesure volumineuses.
Références
[1] M. Goto, N. Kobayashi, G. Ren, M. Ogihara, “Scaling Up Heterogeneous Waveform Clustering for Long-Duration Monitoring Signal Acquisition, Analysis, and Interaction: Bridging Big Data Analytics with Measurement Instrument Usage Pattern”, IEEE International Conference of Big Data, Los Angeles, CA. USA. 2019, pp. 1794-1803.
[2] Keysight Technologies, “Evaluating current probe technologies for low-power measurements.” http://literature.cdn.keysight.com/litweb/pdf/ 5991-4375EN.pdf.
[3] Keysight Technologies, “CX3300 Series Device Current Waveform Analyzer Datasheet.” https://literature.cdn.keysight.com/litweb/pdf/ 5992-1430EN.pdf?id=2727780.
[4] K. Hasegawa, K. Chikamatsu, and N. Togawa, “Empirical Evaluation on Anomaly Behavior Detection for Low-Cost Micro-Controllers Utilizing Accurate Power Analysis”, IEEE International Symposium on On-Line Testing and Robust System Design (IOLTS), 2019, pp. 54-57.