

Des chercheurs de l’Imperva Defense Center ont analysé le trafic d’un nœud de sortie Tor et ont présenté les résultats dans une série d’articles de blog. Cet article s’intéresse aux campagnes d’attaques de « scraping » provenant de milliers d’adresses IP Tor.
Tribune Imperva – Les chercheurs ont procédé à une extrapolation à partir de quelques centaines d’adresses IP, chacune émettant 474 requêtes par minute, soit près de 4,8 millions de requêtes HTTP par mois pour une attaque de scraping. Chacune d’elles peut entraîner la perte du site de la victime en raison de trafic Web frauduleux.
Le Web scraping consiste à extraire le contenu et les données d’un site Web à l’aide de bots. Également appelée « screen scraping » (capture de données d’écran) ou encore « site scraping » (récupération de sites), cette technique peut compromettre les revenus et bénéfices de la victime en détournant sa clientèle et en fragilisant sa compétitivité. Les attaques de Web scraping vont de la collecte inoffensive de données à des fins de recherche personnelle au ratissage répété et calculé d’informations dans le but de casser les prix par rapport à la concurrence ou de publier de précieuses informations de manière illicite.
Un temps considéré comme un inconvénient mineur, le Web scraping est devenu en l’espace de quelques années l’une des plus grandes menaces pour les applications d’entreprise. Les bots de scraping persistants consomment les ressources de calcul allouées aux applications, n’apportent aucune valeur ajoutée et, dans la plupart des cas, nuisent à l’application en dérobant le contenu des pages Web et en récupérant les grilles de tarifs au profit de la concurrence. Le Web scraping est, de fait, un marché florissant qui crée de nouveaux débouchés en matière de services. Malgré des degrés de sophistication et de persistance disparates, la finalité reste la même : extraire de précieuses données de l’application.
Les sections suivantes présentent deux attaques de Web scraping en provenance de Tor. Dans le premier cas, les schémas d’attaque sont analysés du point de vue de l’organisateur d’une campagne de scraping visant le site Web d’un revendeur réputé. Dans le second cas, l’attaque est examinée sous l’angle de la victime, un site de vente au détail de produits de luxe.
Aperçu d’une attaque de scraping
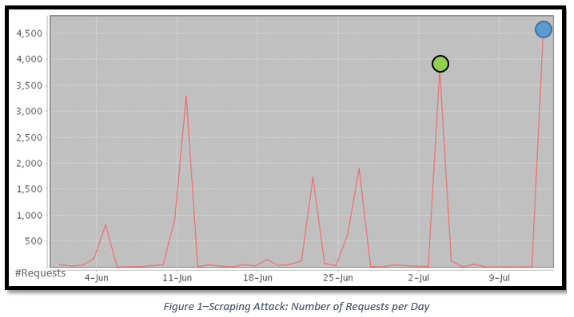
Pendant plus d’un mois, l’activité de clients Tor utilisant le même nœud de sortie Tor (même adresse IP) pour récupérer les données du site Web d’un revendeur réputé a été enregistrée. L’intensité de l’attaque, alliée au caractère multi-origine d’un bon nombre d’attaques de scraping, laisse à penser qu’elle a été lancée simultanément depuis plusieurs clients Tor. Il est probable qu’au cours des périodes d’inactivité, illustrées sur la Figure 1, l’attaque a disparu de nos radars, mais s’est poursuivie à partir d’autres sources. Lors du pic d’activité représenté par la pastille bleue sur la Figure 1, nous avons détecté 4 616 requêtes en six minutes. Comme indiqué par la pastille verte, nous avons identifié un second pic dix jours plus tôt, 2 929 requêtes en dix minutes, ce qui correspond tout à fait à la durée de vie par défaut d’un circuit Tor. Les chercheurs pensent qu’à ce stade, le pirate a basculé sur un autre circuit Tor et a continué le scraping, comme en témoigne une autre adresse IP Tor visible sur le site Web de la victime.
Pour savoir si le trafic en provenance de cette adresse IP est le fait d’utilisateurs légitimes consultant le site de manière anonyme depuis Tor ou bien de scrapers Web, nous avons analysé le comportement du trafic émanant de Tor, ainsi que le contenu des pages visitées. Les schémas de trafic, illustrés sur la Figure 1, montrent des périodes d’inactivité interrompues par de brusques pics de trafic Tor, une caractéristique des attaques Web automatisées telles que le scraping. De plus, ces pages contenaient des listes de produits, avec leur prix, ce qui n’a rien d’étonnant puisqu’il s’agit du contenu Web le plus exposé au scraping. Ces pages ont plus vraisemblablement été récupérées par des concurrents souhaitant ajuster leurs tarifs afin de bénéficier d’un avantage concurrentiel déloyal plutôt que par des pirates motivés par la curiosité. Le trafic suspect s’est en outre caractérisé par l’absence de demandes de ressources d’images, un facteur que nous attribuons à une exploration sélective des scrapers.
Un examen approfondi des en-têtes user-agent dans le trafic suspect révèle que dans de nombreuses attaques Web, le client du pirate s’est fait passer pour différents navigateurs afin de déjouer les mécanismes de blocage du trafic généré par des outils automatisés :
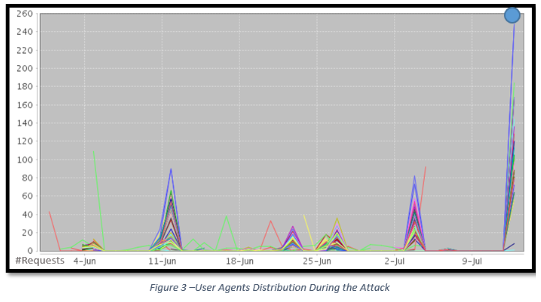
L’analyse du trafic Tor fait apparaître deux campagnes de scraping sur le site Web, émanant du réseau Tor et faisant probablement partie d’une seule et même campagne d’attaques. Les pirates utilisent un plus grand nombre de clients masqués qui profitent de l’anonymat assuré par Tor, changent constamment au moyen d’en-têtes user-agent factices visant à contrecarrer les mécanismes de protection et extraient systématiquement les données métiers de l’application ciblée.
La section ci-après décrit une autre campagne de scraping émanant du réseau Tor. Cette fois, elle est examinée du point de vue de l’application pour offrir une vue complète de l’attaque de scraping.
Campagne de scraping
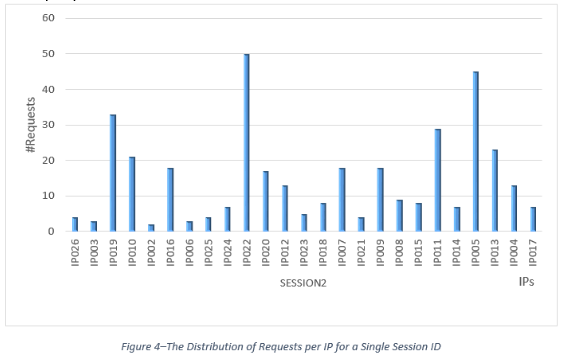
La victime de l’attaque est une application de vente au détail de produits de luxe ayant reçu près de 2 millions de requêtes suspectes au cours de la même semaine, probablement toutes issues de la même attaque. En fait, trois URL ont été ciblées par 99 % des requêtes, ce qui est caractéristique des attaques de scraping. Une étude attentive de ces URL (Figure 2) montre une page de recherche, ainsi que deux pages d’achat de produits, les produits et les tarifs étant clairement la cible de l’attaque de scraping. Les pirates ont utilisé la fonction de recherche pour trouver les produits et ont accédé aux résultats de la recherche à partir des pages produit. Ils se sont servis de 777 adresses IP Tor et ont généré en moyenne 2 563 requêtes par adresse IP au cours de la même semaine. Un examen plus approfondi du trafic révèle que 1 086 identifiants de session (jsessionid) ont été utilisés en moyenne 1 117 fois chacun lors de l’attaque, le plus souvent depuis des adresses IP différentes. Par exemple, la Figure 4 montre qu’un ID de session spécifique a été utilisé par pas moins de 25 adresses IP différentes.
Comme dans l’attaque précédente, les chaînes user-agent sont factices et 453 547 agents utilisateur distincts ont été identifiés au moment de l’attaque, ce qui indique le recours à des chaînes user-agent aléatoires. Après nettoyage de ces chaînes, nous avons identifié trois principaux agents utilisateur employés indifféremment tout au long de la même session avec diverses permutations ou versions :
- Agent utilisateur Mozilla : Mozilla/5.0 (Windows; Windows NT 5.1; en-US; +MrTiger) Firefox/10.0 (66 % des requêtes)
- Agent utilisateur MSN-BOT : msnbot-Products/1.0 (+http://search.msn.com/msnbot.htm) (17 % des requêtes)
- Agent utilisateur Opera : Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00 x:0) (17 % des requêtes)
Pour finir, l’analyse de la répartition des adresses IP (Figure 5) par attaque a été réalisée. La plupart des attaques ont été lancées à partir de trois adresses IP sources Tor principales. Nous n’avons pas été étonnés de constater que ces trois adresses IP étaient enregistrées auprès de services d’hébergement aux États-Unis, ce qui est généralement le cas des nœuds de sortie Tor. La répartition anormale des requêtes entre les adresses IP est surprenante. Elle a attiré notre attention et sera abordée dans notre prochain article intitulé « Think bandwidth ».
Deux attaques de scraping en provenance de Tor ont été détecté. Leurs caractéristiques sont conformes au profil d’une campagne de scraping type, avec répartition, recyclage des identifiants de session, chaînes user-agent multiples et, bien entendu, anonymat. Les pirates ont profité du caractère anonyme de Tor pour masquer toute trace permettant de remonter jusqu’à eux.
Réduction des risques
Les pare-feu pour applications Web sont communément utilisés pour protéger les applications Web contre la plupart des attaques. Aujourd’hui, les pare-feu avancés pour applications Web sont capables de détecter les attaques les plus complexes visant la logique métier, et ce, même si elles émanent de réseaux Tor. Les pare-feu pour applications Web intégrant des flux de renseignements sur les menaces tiennent compte de la réputation des adresses IP et recoupent les attaques pour les neutraliser efficacement.
Pour en savoir plus sur la neutralisation des attaques de scraping, téléchargez le livre blanc « Detecting and Blocking Site Scaping ».


{kind=link}
Les commentaires sont fermés.